
前言
需要说明的是,折腾仅限用于学习用途,可通过正规途径购买的模型请勿非法提取,请勿对模型及贴图等数据进行修改、二次分发、商用等违反Sketchfab版权规定及著作权相关法律法规的行为。使用本文提到的方法提取模型产生的一切后果由操作人承担,与本网站及本人无关
最近在Sketchfab看到了一个智乃的模型,顿时感觉想要拥有,但模型作者并没有开放下载和购买,迫于实在是心痒难耐,便在网上寻找破解Sketchfab加密的方法
首先在某宝上搜索,发现有几家店铺提供了收费下载服务,虽然没有明说,但看描述信息可以实现“任意下载”,心中底气又足了两分某宝下载服务均价20 RMB,希望不要因为砸了别人饭碗而被追杀🌝
网络上的资料不多,零星几个提到的信息指向了Ninja Ripper。这一工具原理是劫持系统DirectX接口,直接从内存中拿到渲染数据,理论上可以支持任意D3D应用,并且无视任何加密,毕竟不管怎么加密,最后系统喂给显卡的都是标准的数据。可惜的是Sketchfab在几个月前已经升级了系统,提取出来的都是一些残片,没有使用价值
抱着不死心的想法继续搜索,终于在一个毛子论坛上找到了希望:一个解密脚本。这个工具的原理就很直接了,因为Sketchfab使用了WebGL来显示模型,那么理论上就一定能够破解,毕竟加解密算法都在前端。这个脚本的作者逆向了出解密算法,并用Python实现出解密工具,做成了Blender的插件,虽然都是很古老的版本,但要什么自行车,能用就行
那么就利用空余时间,简单记下折腾过程
2021-6-30 更新
注意sketchfab目前对所有模型文件做了二次加密,格式为binz,解密后的格式仍为.bin.gz
解密关键逻辑在请求模型文件完成后立即执行,懂一点前端调试知识的可以打断点dump出来,暂无自动化处理方法
附上手动操作步骤:
找到类似下图的代码,在附近断点
刷新可以看到在断点处停下来了,此时的局部变量i可以看到是一个JSON字符串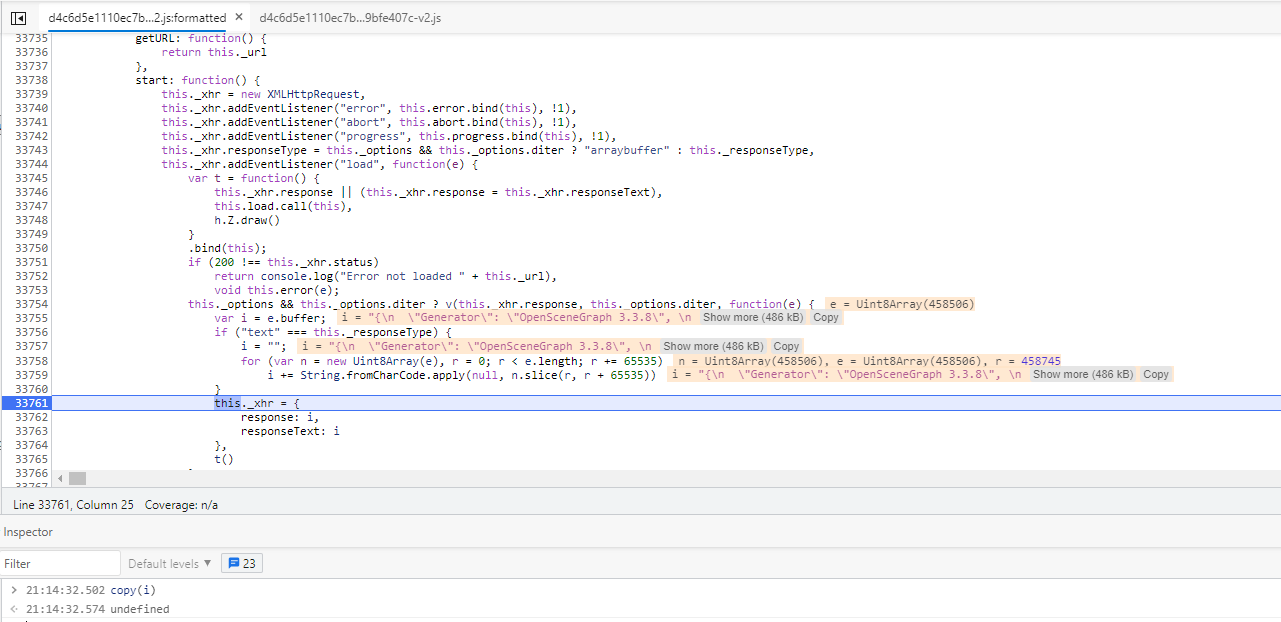
控制台执行copy(i)可以复制出来,内容类似下面,这个就是之前的file.osgjs文件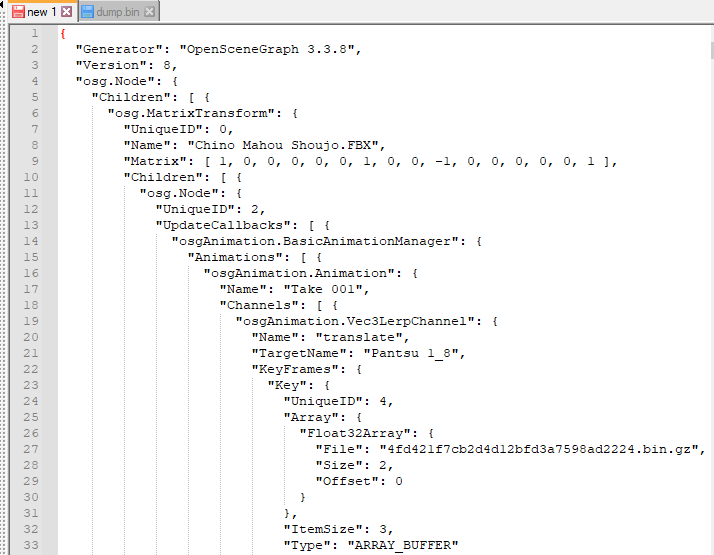
继续代码执行,可以看到又断下来了,此时的i是一个ArrayBuffer类型的数据
执行下图代码保存为文件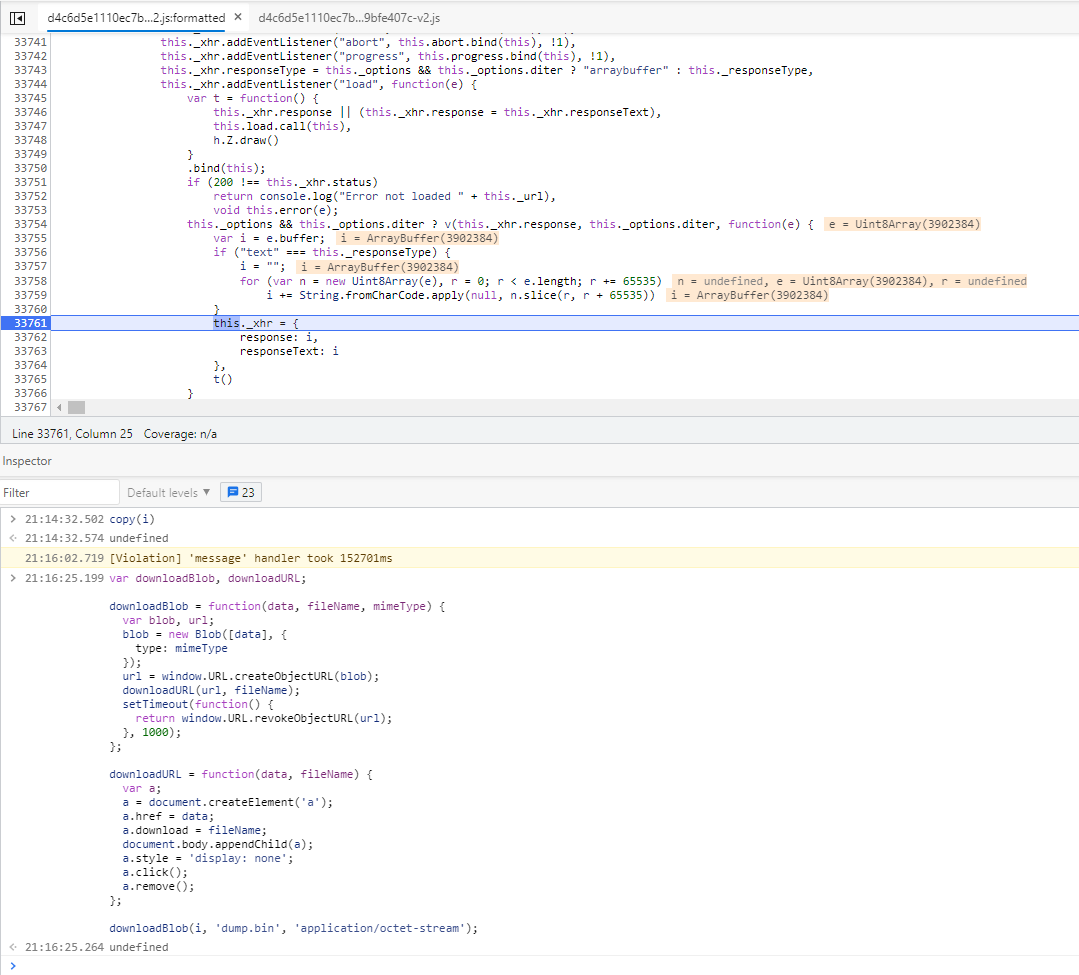
对比下看看,这个就是之前的model_file.bin.gz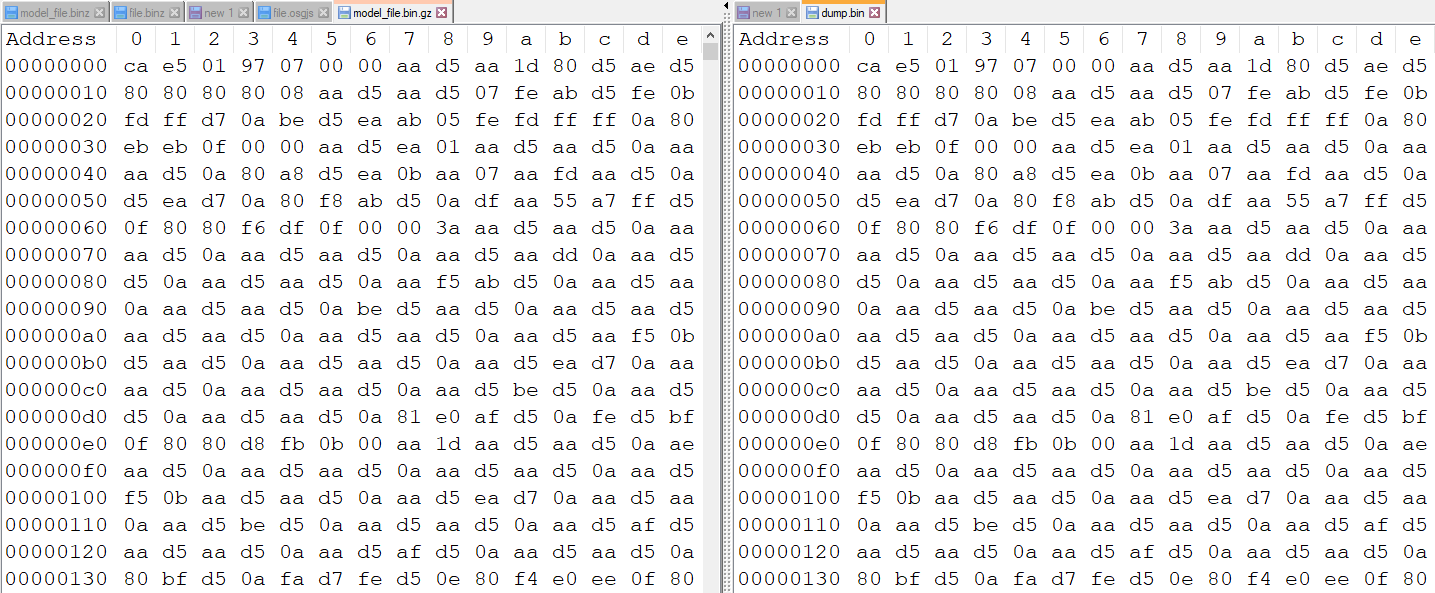
之后就和以前的步骤一样了
保存ArrayBuffer到文件
var downloadBlob, downloadURL;
downloadBlob = function(data, fileName, mimeType) {
var blob, url;
blob = new Blob([data], {
type: mimeType
});
url = window.URL.createObjectURL(blob);
downloadURL(url, fileName);
setTimeout(function() {
return window.URL.revokeObjectURL(url);
}, 1000);
};
downloadURL = function(data, fileName) {
var a;
a = document.createElement('a');
a.href = data;
a.download = fileName;
document.body.appendChild(a);
a.style = 'display: none';
a.click();
a.remove();
};
downloadBlob(i, 'dump.bin', 'application/octet-stream');提取
所需工具
- Python 2.6.6
- Blender 2.49
- Blender249[osgjs].zip 解密脚本
工具准备
- 安装Python环境 (以下方法二选一,推荐a方法,可移动使用且不影响其他Python版本)
- a.下载Python 2.6.6源码包,将其中的Lib目录中的内容压缩为python26.zip并放置于Blender安装目录
- b.执行安装程序并添加环境变量
PythonPath,值为C:\Python26;C:\Python26\DLLs;C:\Python26\Lib;C:\Python26\Lib\lib-tk(假设安装目录为C:\Python26)
- 安装Blender 2.49
- 将Blender249[osgjs].zip中的newGameLib目录解压至Blender安装目录中的
.blender\scripts目录下 - Blender249.blend单独放置
下载模型数据
- 打开浏览器并打开Dev Tools
- 打开所需模型的Sketchfab页面,确保模型已经完全加载
- 在Network选项卡中找到如下两个文件并下载下来放到一起
- file.osgjs.gz
- model_file.bin.gz
- 其中file.osgjs.gz是一个JSON文件,将其重命名为file.osgjs
- 贴图资源在
media.sketchfab.com下,有不同分辨率之分,注意鉴别 - 也可以忽略以上步骤,直接从网页包含的数据中提取,具体可参考下列代码:
模型数据下载脚本
为了快速下载模型数据,我写了一个简单的下载脚本:
import os
import re
import json
import requests
from urllib.parse import urlparse
from html import unescape
from bs4 import BeautifulSoup
SCRIPT_VERSION = '1.0'
HEADERS = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.25 Safari/537.36',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh-TW;q=0.8,zh;q=0.6,en;q=0.4,ja;q=0.2',
'cache-control': 'max-age=0'
}
def main():
modelId = input('input model ID (e.g., 9120703a4aee4c2cb0313a9ca3e1e1a3): ')
url = 'https://sketchfab.com/models/{id}/embed'.format(id=modelId)
parse(url)
def parse(url):
try:
print('Parsing...')
page = requests.get(url, headers=HEADERS, timeout=10).text
soup = BeautifulSoup(page, 'html.parser')
modelId = urlparse(url).path.split('/')[2].split('-')[-1]
data = unescape(soup.find(id='js-dom-data-prefetched-data').string)
data = json.loads(data)
name = validateTitle(data['/i/models/'+modelId]['name'])
thumbnailData = data['/i/models/'+modelId]['thumbnails']['images']
thumbnail = getBiggestImage(thumbnailData)
osgjsUrl = data['/i/models/'+modelId]['files'][0]['osgjsUrl']
modelFile = osgjsUrl.replace('file.osgjs.gz', 'model_file.bin.gz')
texturesData = data['/i/models/'+modelId+'/textures?optimized=1']['results']
textures = []
print('Model Id:', modelId)
print('Name:', name)
print('Thumbnail URL:',thumbnail)
print('osgjs URL:', osgjsUrl)
print('Model File:', modelFile)
print('Textures:', len(texturesData))
download(thumbnail, os.path.join(name, 'thumbnail.jpg'))
download(osgjsUrl, os.path.join(name, 'file.osgjs'))
download(modelFile, os.path.join(name, 'model_file.bin.gz'))
for texture in texturesData:
textureUrl = getBiggestImage(texture['images'])
download(textureUrl, os.path.join(name, 'texture', validateTitle(texture['name'])))
except AttributeError:
raise
return False
def getBiggestImage(images):
size = 0
for img in images:
if img['size'] != None and img['size'] > size:
size = img['size']
imgUrl = img['url']
return imgUrl
def validateTitle(title):
pattern = r'[\\/:*?"<>|\r\n]+'
newTitle = re.sub(pattern, "_", title)
return newTitle
def download(url, filename):
print('Downloading:', filename)
try:
os.makedirs(os.path.dirname(filename), exist_ok=True)
if os.path.exists(filename):
if os.path.getsize(filename) > 0:
print('file exists.')
else:
with open(filename, 'wb') as file:
file.write(requests.get(url, headers=HEADERS, timeout=30).content)
else:
with open(filename, 'wb') as file:
file.write(requests.get(url, headers=HEADERS, timeout=30).content)
except Exception:
pass
if __name__ == '__main__':
main()提取过程
- 启动Blender,将随之启动一个CMD窗口,可观察有无报错
- 点击File - Open,打开
Blender249.blend,然后按Ctrl + U,这样以后就不用重复此步了 - 右键点击窗口左侧的Python代码区域,然后点击Execute Script或按Alt + P
- 在出现的文件选择对话框中导入此前下载的
file.osgjs - 如果一切正常,CMD窗口将刷过大量解密操作相关信息,并在视图中显示解密后的模型
- 点击File - Export,将解密后的模型文件导出为其他格式
- 贴图和动画数据不会被保存,导出的模型可以在任何3D制作软件中进行编辑

可能遇到的错误
提示IndexError: list index out of range,完整报错类似如下:
Traceback (most recent call last):
File "starter.py", line 1767, in openFile
File "starter.py", line 1760, in Parser
File "starter.py", line 1723, in osgParser
File "C:\blender-2.49-win64\.blender\scripts\newGameLib\myLibraries\meshLib.py", line 670, in draw
File "C:\blender-2.49-win64\.blender\scripts\newGameLib\myLibraries\meshLib.py", line 588, in addFaces
File "C:\blender-2.49-win64\.blender\scripts\newGameLib\myLibraries\meshLib.py", line 822, in indicesToTriangleStrips
IndexError: list index out of range解决方法:blender左侧的Python代码注释掉330-351行
看图

